
In my last post, I showed you how to setup an automated, enterprise wide deployment of AWS Config. That post assumed you were starting from scratch with no existing setup of AWS Config in your AWS accounts. However, what if you have already enabled AWS Config in one or more of your AWS accounts, with each account logging to their own S3 bucket? How can you migrate from a manually deployed, decentralized setup to the automated and centralized configuration? More importantly, how can you do so without losing any of your historical Config data that you have already collected?
Objective
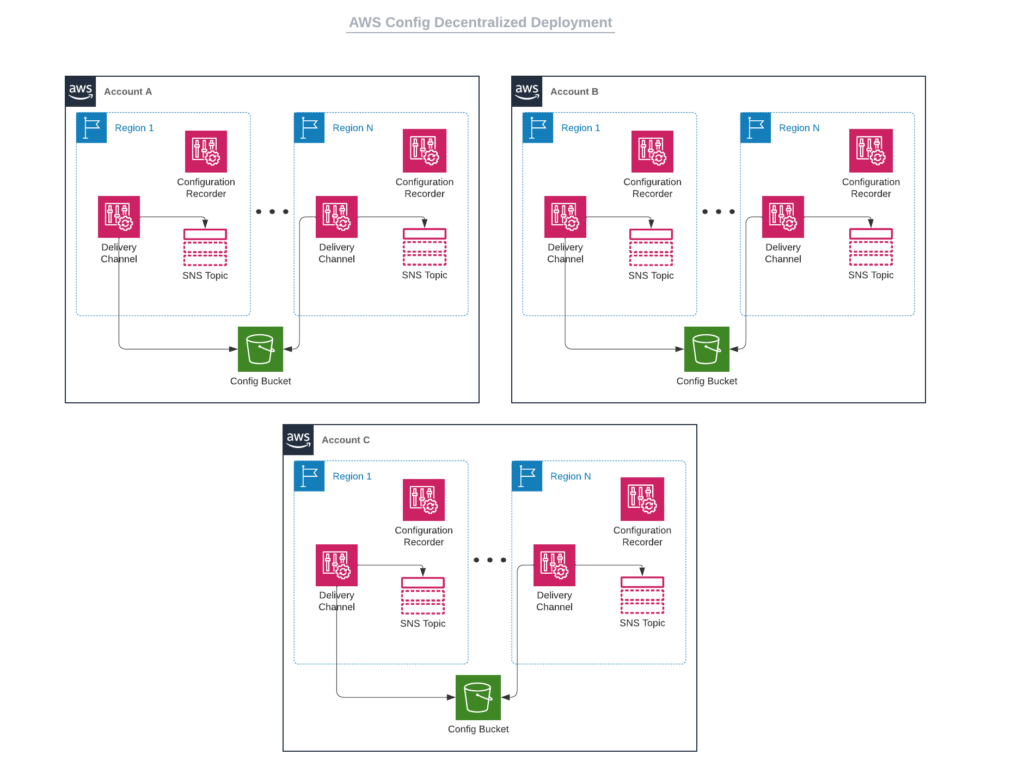
In my original enterprise environment, I had been enabling AWS Config in each account manually by navigating to each region and enabling the necessary AWS Config features (configuration recorder, delivery channel). I had the delivery channel for each region sending data to a centralized S3 bucket in the individual AWS account. My setup looked similar to the following diagram:
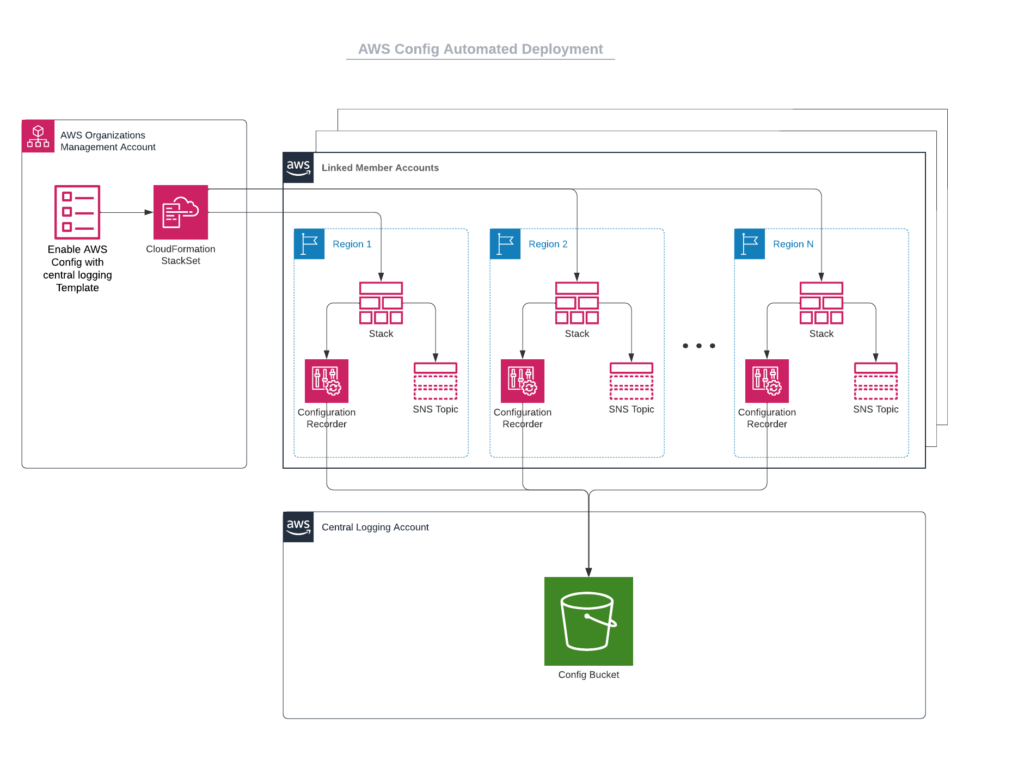
As a reminder, here is the end goal architecture that we want to reach by moving to the organization wide centralized model. In the next section, I will walk you through the steps to get to the end goal architecture.
Migration Process
At a high level, the main steps to move from a decentralized to a centralized AWS Config deployment are as follows:
- Create new centralized S3 bucket for storing Config data.
- Remove existing AWS Config setups in each account and region.
- Copy historical AWS Config data from local S3 buckets to centralized S3 bucket.
- Re-enable AWS Config using my StackSet method.
You will perform each of these steps in every account that you are migrating from decentralized into the new centralized architecture.
Create new S3 bucket
As outlined in my previous blog post, we need to create a new S3 bucket to store all your unified AWS Config data. Create this bucket in your centralized logging account and ensure the S3 bucket policy is configured to allow all accounts in your AWS organization to write to the bucket. This can be easily accomplished using the aws:PrincipalOrgID global conditional connect key…see my earlier blog post for a full sample bucket policy.
Remove existing AWS Config settings
We want to remove the existing AWS Config resources from each region in the account. Specifically, we must delete the Configuration Recorder, Delivery Channel and SNS topic (if it exists). Failure to remove these resources will cause the subsequent StackSet deployment to fail. Note we are deleting these resources while still retaining the local S3 bucket that the Delivery Channel has been writing to.
The easiest way to delete these resources quickly is by using the AWS CLI. First, obtain the configuration recorder name using the following command:
aws configservice describe-configuration-recorders --region us-west-2
Config service will return JSON formatted output that will include the name. Capture this information for future use, and repeat the same command against every region where you have AWS Config enabled in the account. Next, we need to use a similar command to obtain the delivery channel name:
aws configservice describe-delivery-channels --region us-west-2
Config service will return JSON formatted output that includes the delivery channel name as well as the SNS Topic ARN associated with this delivery channel (if SNS is being used). Capture the delivery channel name and topic ARN for later use, and repeat this same command against every region where you have AWS Config enabled.
Now that we have the Configuration Recorder Name, Delivery Channel Name, and SNS topic ARNs gathered, we will use the following commands to remove all these resources.
aws configservice delete-configuration-recorder --configuration-recorder-name default --region us-west-2 aws configservice delete-delivery-channel --delivery-channel-name default --region us-west-2 aws sns delete-topic --topic-arn arn:aws:sns:us-west-2:111111111111:config-topic --region us-west-2
Repeat these commands against every region where you have AWS Config enabled, updating the commands with the proper region and resource names.
Copy historical AWS Config data
With these AWS Config resources deleted, we can now move on to copying the historical AWS Config data to our new centralized S3 bucket. This is easily accomplished using the aws s3 sync command:
aws s3 sync s3://original-config-bucket/AWSLogs/111111111111 s3://centralized-config-bucket/AWSLogs/111111111111
Note that is is important to preserve the prefix used (AWSLogs/accountidnumber) in the destination path. In this way we ensure that each account’s historical config data is placed under a distinct prefix that matches what AWS Config will be expecting later on when we enable the centralized configuration via StackSet.
Re-enable AWS Config using StackSet
Once all the historical data has been copied over to the centralized S3 bucket, you can safely re-enable AWS Config by leveraging the automated StackSet approach outlined in my previous blog post. Once Config is up and running again, you will find that all your historical AWS Configuration data will be visible to you in the AWS Config console.
Conclusion
In this post, I’ve shown you how you can migrate from a decentralized, manually deployed AWS Config architecture to a fully automated and centralized architecture while preserving all your pre-existing historical data already captured by AWS Config. I’d like to give a shout-out to the AWS Enterprise Support team who helped me to work out this method! I hope you find this post useful, and as always please give me your comments or suggestions for improvement in the comments. Happy Building!
Thanks for this post!.
It actually gave me ideas how to manage my infra.
This is valuable.