
Introduction
Last month, I had the honor to be invited as a Delegate for Cloud Field Day 25 in Santa Clara. One of the more interesting sessions came from Hammerspace, where the discussion centered around a problem a lot of enterprises encountering as AI adoption grows:
Your GPUs are only as useful as your ability to get data to them efficiently.
That sounds obvious, but it becomes a real operational challenge once your datasets are spread across multiple cloud providers, on-prem storage platforms, object stores, and regional environments.
At my day job, I spend a lot of time thinking about cloud architecture at scale, and one recurring reality is that data tends to accumulate everywhere. You may have:
- Large datasets sitting in Amazon S3 or other cloud datastores
- Legacy NAS platforms on-prem
- Teams operating in multiple geographic regions
- New AI teams suddenly asking for high-performance access to all of it
That’s where I found the Hammerspace presentation interesting—they’re trying to solve the operational headache of making all that distributed data feel local to compute resources.
The Architecture

At a high level, the Hammerspace platform consists of:
- Metadata (Anvil) servers
- Data services (DSX) nodes
- Existing underlying storage platforms
- Integration with cloud-native storage services
The key idea is that Hammerspace sits above your existing storage infrastructure rather than forcing a complete storage replacement.
That immediately caught my attention because ripping and replacing storage platforms is a hard sell in enterprise environments with lots of existing storage investments.
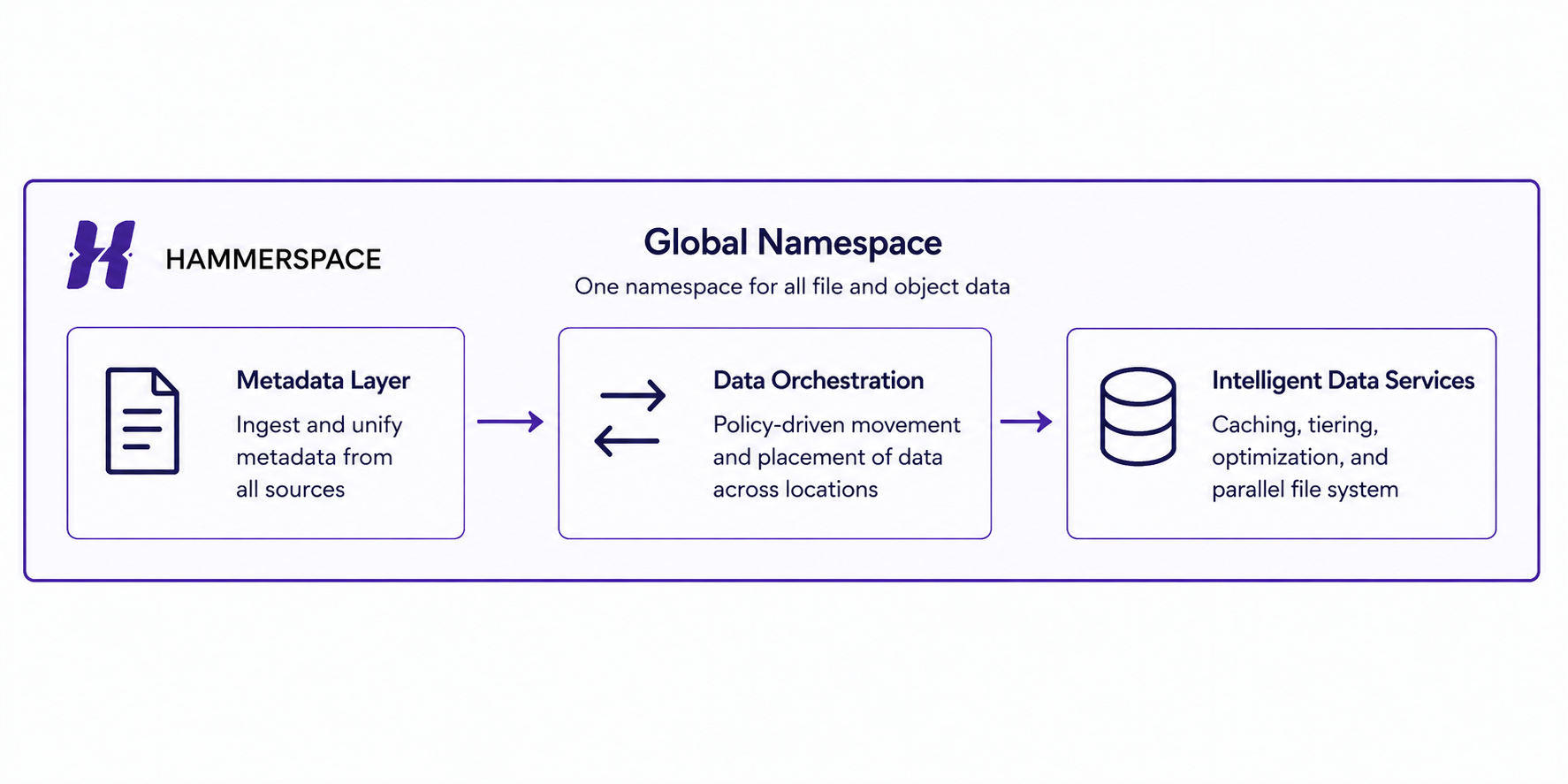
Another important nuance that came up during the session is that this appears to be a metadata-first architecture. Rather than forcing customers to immediately migrate petabytes of data into a new platform, Hammerspace first assimilates metadata from your existing environments and creates a unified view of your datasets.
That means organizations can make existing datasets discoverable much faster, while delaying actual data movement until it’s necessary. For enterprises sitting on years of storage sprawl, that feels far more realistic than a massive migration project.
They also emphasized support for standard protocols like NFS and pNFS, which I think matters. Enterprise infrastructure teams tend to get nervous anytime a vendor requires proprietary clients or major architectural changes. Their approach appears designed to work with existing environments rather than forcing teams to retool everything.
The Capabilities That Stood Out
Global Namespace
This was probably the most interesting feature to me.
Instead of users needing to know:
“This dataset lives in AWS”
or
“That dataset is in our datacenter”
everything becomes accessible through a single global file system view.
That abstraction becomes incredibly valuable when teams are distributed across regions or cloud platforms.
Data Assimilation
This appears to be their method of ingesting existing datasets into the platform without requiring a major migration event.
Again, I think this is where their messaging felt practical. Most enterprises are not starting from a clean slate—they’re inheriting years of infrastructure decisions, storage platforms, acquisitions, and technical debt.
The ability to quickly expose existing datasets without immediately relocating all of them feels like a much easier operational conversation.
Data Orchestration
This was where the AI conversation became much more interesting.
Rather than simply reacting when compute requests data, Hammerspace appears to use policy-driven automation to proactively place data where it needs to be.
That could mean:
- Moving datasets closer to GPU clusters before training begins
- Replicating data to regions where inference workloads are expected
- Keeping frequently accessed datasets on high-performance storage
- Moving colder datasets to lower-cost storage tiers
That matters because GPU infrastructure is expensive.
Very expensive.
Nobody wants multi-million dollar GPU clusters sitting idle while waiting on datasets to traverse WAN links.
This felt like one of the strongest parts of their story because it shifts the conversation from simple storage management to GPU utilization optimization, which is where many AI infrastructure teams are heading.
Parallel File System
This feels particularly targeted toward AI training and HPC workloads that need massive throughput.
Their messaging around:
“Tier 0 performance with the utility of a file system”
was clearly aimed at organizations trying to balance performance with operational simplicity, and it kind of resonated with me. AI teams typically want raw performance, but Infrastructure teams want operational sanity. Those two goals don’t always align.
The Demo That Made the Most Sense
The most practical demo showed them connecting a second site into the platform and immediately exposing the global file system.
That part was impressive because it looked operationally simple.
The catch? Files weren’t automatically present locally. They had to be pulled across when accessed unless caching or placement policies were configured ahead of time. I appreciated seeing that because it reinforced that there’s still real architecture planning required here.
“Global access” can sound magical in vendor messaging—but physics still exists. Latency and bandwidth constraints still exist. Not to mention that moving large datasets across regions or cloud providers can get expensive very quickly if teams aren’t intentional about placement policies.
Where I Think This Fits
I don’t think this is something the average AWS customer needs.
If your workloads live entirely inside a single cloud provider and your data architecture is relatively clean, native services may be enough. But I can absolutely see value here for organizations that have:
- Multi-cloud footprints
- Large AI training datasets
- Hybrid infrastructure
- Regional data locality requirements
- Existing storage silos they can’t easily eliminate
My Biggest Takeaway
The bigger takeaway from this session wasn’t necessarily the product itself. It was the reminder that AI infrastructure discussions are quickly shifting away from simply:
“How do we buy GPUs?”
toward:
“How do we efficiently feed those GPUs?”
That second question may end up being the harder problem to solve. Based on what I saw at Cloud Field Day, companies like Hammerspace are positioning themselves directly in that gap. It’ll be interesting to see how much demand emerges here as enterprise AI workloads continue to scale.